

Introduction and Background
The packet capture I’ll be covering today is part of a CTF I recently took part in. I thought that this would be an interesting topic because although there have been multiple CTF challenges covering USB packet analysis, this is the first to involve a live camera feed.
The USB protocol specifies 4 primary types of transfers. Control Transfers are used for configuring USB devices. Bulk transfers are used for transferring large amounts of data, for example copying files to a thumbdrive. Interrupt transfers are used for devices that need low latency exchanges like keyboards, mice, and other input devices. Lastly, Isochoronous Transfers are used for real-time data such as video camera data, audio I/O and so on.
Packet filtering and Initial analysis
Opening up the pcap in wireshark, we can observe that the first 18 packets are part of the set up phase. During the USB enumeration process, the host sends a series of requests to gather information about the device. The host then identifies the device and requests additional descriptors, these descriptors provide further detail about the device and supported interfaces
Since we’re looking out for a video camera, we can check all the GET DESCRIPTOR Response Device to find our video cam. Info about a device can be found under the tags bDeviceClass and idProduct.
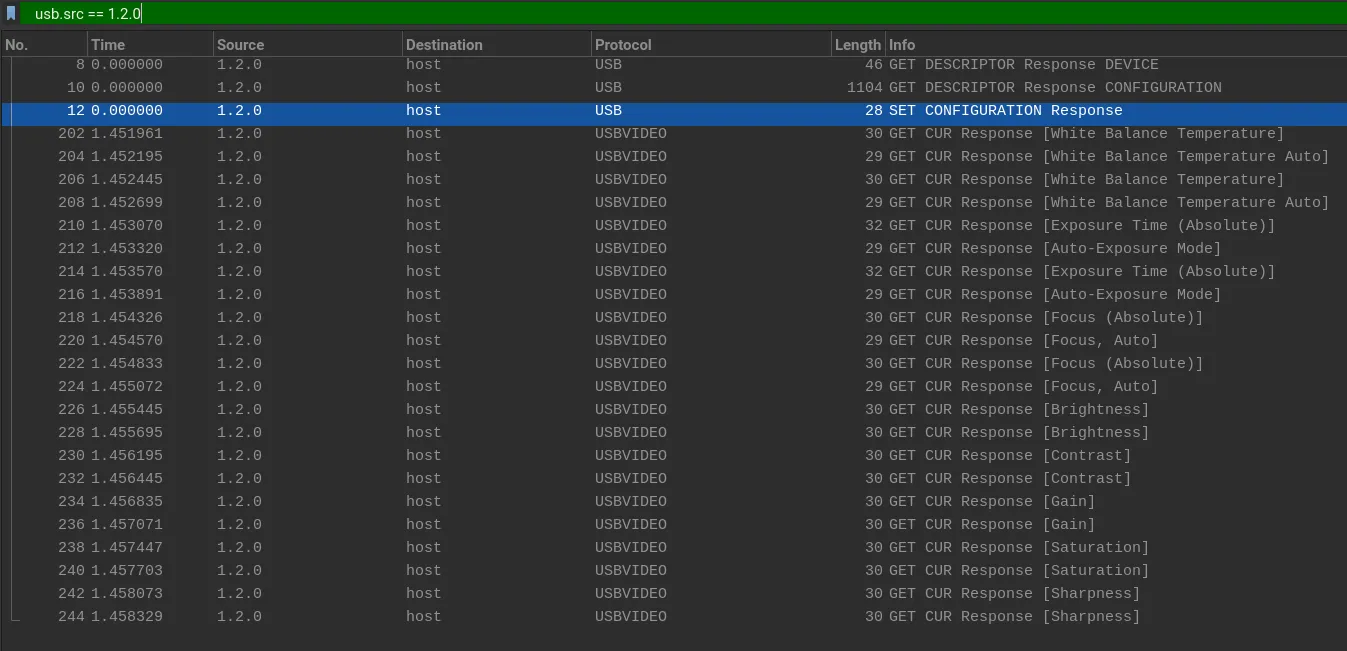
1.1.0 is a USB hub, 1.2.0 is a Misc device, 1.3.0 is a Headset. Given this, we can infer that 1.2.0 is the one we want. Now we can filter for packets to get a cleaner view. Display filter: usb.src == 1.2.0
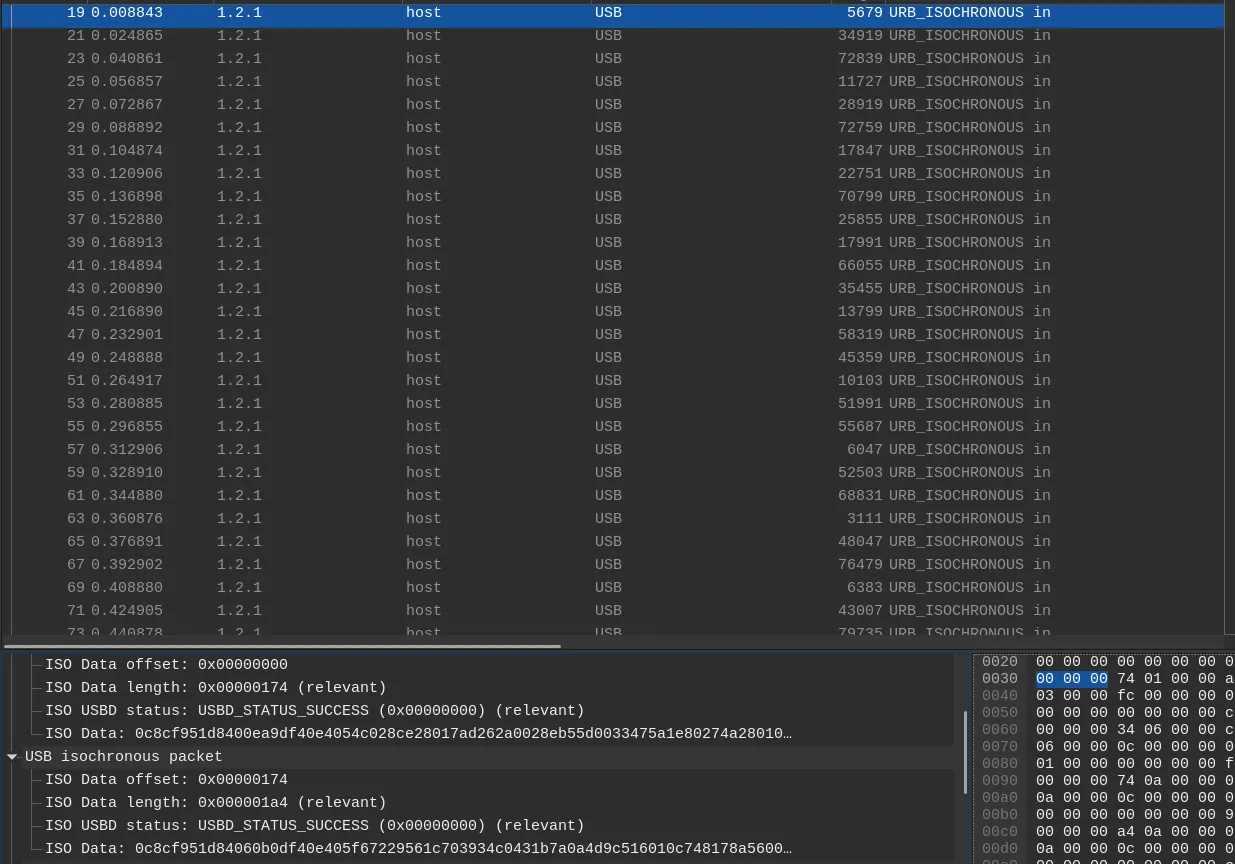
Going back to the unfiltered display, we can see our stream of URB_ISOCHRONOUS packets. At this point you might be wondering, if 1.2.0 represents the video camera, why are the URB isochronous packets coming from 1.2.1?
Simply put, 1.2.0 is the control endpoint and 1.2.1 is the isochronous endpoint. The control endpoint handles configuration-related requests as well as other settings like brightness, contrast and other parameters. This is why you notice the “Get Current Value” packets coming from 1.2.0 but the actual data is coming from 1.2.1
Getting back on topic, we can notice that the webcam specifies two different formats along with dimensions. MJPEG stands for Motion JPEG and is a video compression format where each video frame is simply a JPEG image.
Now that we have the information we need, it’s time to tackle extracting the data from the iso packets
Extracting and Processing the Isochronous packets
Each Frame comes with a single USB URB header followed by multiple USB isochronous packets.
This is where I initially got stuck, and why documentation is incredibly important. Notice how the first few bytes of every packet layer starts with the same few bytes?
If we refer to this helpful documentation, we can find out that each frame contains a single payload transfer of maximum 1024 bytes. The first 12 bytes are reserved for the payload header length. Using this info, we can then write a simple python script to form a single combined payload.
def extract_isochronous_payload(pcap_file):
# Read the pcap file
cap = pyshark.FileCapture(pcap_file, display_filter='usb.transfer_type == 0x00 && usb.src == 1.2.1')
payloads = []
for packet in cap:
# Check if this packet has USB layer
if 'usb' in packet:
# Iterate through each layer
for layer in packet.layers:
if layer.layer_name == 'usb':
# Extract all isochronous transfers within the packet
if hasattr(layer, 'iso_data'):
iso_data_hex = layer.iso_data.replace(':', '')
# Strip the first 12 bytes (24 hex characters) and convert to bytes
data = bytes.fromhex(iso_data_hex[24:])
# Append the data to our list of payloads
payloads.append(data)
# Combine all the payloads
combined_payload = b''.join(payloads)
return combined_payload
Extracting images from our combined payload
Thanks to our earlier efforts, we can assume that the payload is a stream of JPEGs. I used a hex editor to confirm that there were indeed JPEGs inside. JPG/JPEGs share the same Magic Bytes, they start with 0xFF 0xD8 and end with 0xFF 0xD9. Now we can start constructing our stream of images!
We first need a function to keep track of all the start and end indices. This basically partitions the file into multiple sections.
def find_jpeg_in_payload(payload):
# JPEG images start with FF D8 and end with FF D9
start_marker = b'\xFF\xD8'
end_marker = b'\xFF\xD9'
start_indices = []
end_indices = []
index = 0
# Search for all the occurrences of the start and end markers
while index < len(payload):
start_index = payload.find(start_marker, index)
if start_index == -1: # No more JPEGs found
break
end_index = payload.find(end_marker, start_index)
if end_index == -1:
print("Found start marker but no end marker. This might indicate a corrupted or incomplete JPEG image.")
break
# Append the start and end of a JPEG to the respective lists
start_indices.append(start_index)
end_indices.append(end_index + len(end_marker))
index = end_index + len(end_marker) # Move past this JPEG
return start_indices, end_indices
After that, we simply call a loop to extract the bytes and generate a new file based on that
def extract_jpegs_to_files(payload, output_folder):
start_indices, end_indices = find_jpeg_in_payload(payload)
# Extract JPEGs and write to individual files
for i, (start, end) in enumerate(zip(start_indices, end_indices)):
jpeg_data = payload[start:end]
filename = f"{output_folder}/image_{i + 1}.jpg"
with open(filename, 'wb') as f:
f.write(jpeg_data)
print(f"JPEG {i + 1} written to {filename}")
Converting images to video
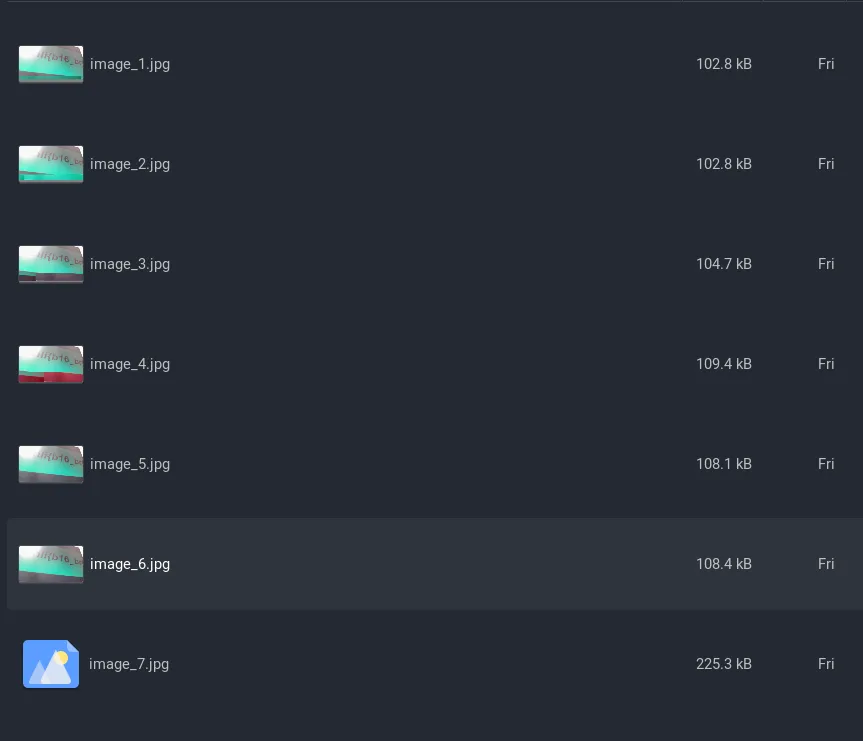
Finally, we have all the frames in jpg format. All that’s left is to combine them into a video! There are multiple ways of doing this, you can use FFmpeg or even online tools to do this. However I decided to write a python script instead.
def make_video(images_folder, output_video_file, fps=30):
# Get all image paths
image_paths = sorted(glob.glob(os.path.join(images_folder, '*.jpg')))
# Read the first image to obtain the size
frame = cv2.imread(image_paths[0])
height, width, layers = frame.shape
# Define the codec and create VideoWriter object
fourcc = cv2.VideoWriter_fourcc(*'mp4v') # or 'XVID', 'MJPG', 'X264', 'WMV1', 'WMV2'
video = cv2.VideoWriter(output_video_file, fourcc, fps, (width, height))
for image_path in image_paths:
video.write(cv2.imread(image_path))
# Release the video writer handle
video.release()
Finally we get our flag: hli{b16_br07h3r_15_w47ch1n6}
Ending remarks
Tackling this challenge was quite tedious without the proper information. I had to read up on a lot of USB documentation as well as many specifications to figure out why I was getting garbled outputs.
Ultimately I really enjoyed this challenge as I learnt a lot about USB specifications, transfer types, and other processes that we typically don’t realize are happening in the background.